Flow matching offers a robust and stable approach to training diffusion models. However, directly applying flow matching to neural vocoders can result in subpar audio quality. In this work, we present WaveFM, a reparameterized flow matching model for mel-spectrogram conditioned speech synthesis, designed to enhance both sample quality and generation speed for diffusion vocoders. Since mel-spectrograms represent the energy distribution of waveforms, WaveFM adopts a mel-conditioned prior distribution instead of a standard Gaussian prior to minimize unnecessary transportation costs during synthesis. Moreover, while most diffusion vocoders rely on a single loss function, we argue that incorporating auxiliary losses, including a refined multi-resolution STFT loss, can further improve audio quality. To speed up inference without degrading sample quality significantly, we introduce a tailored consistency distillation method for WaveFM. Experimental results demonstrate that our model achieves superior performance in both quality and efficiency compared to previous diffusion vocoders, while enabling waveform generation in a single inference step.
Model
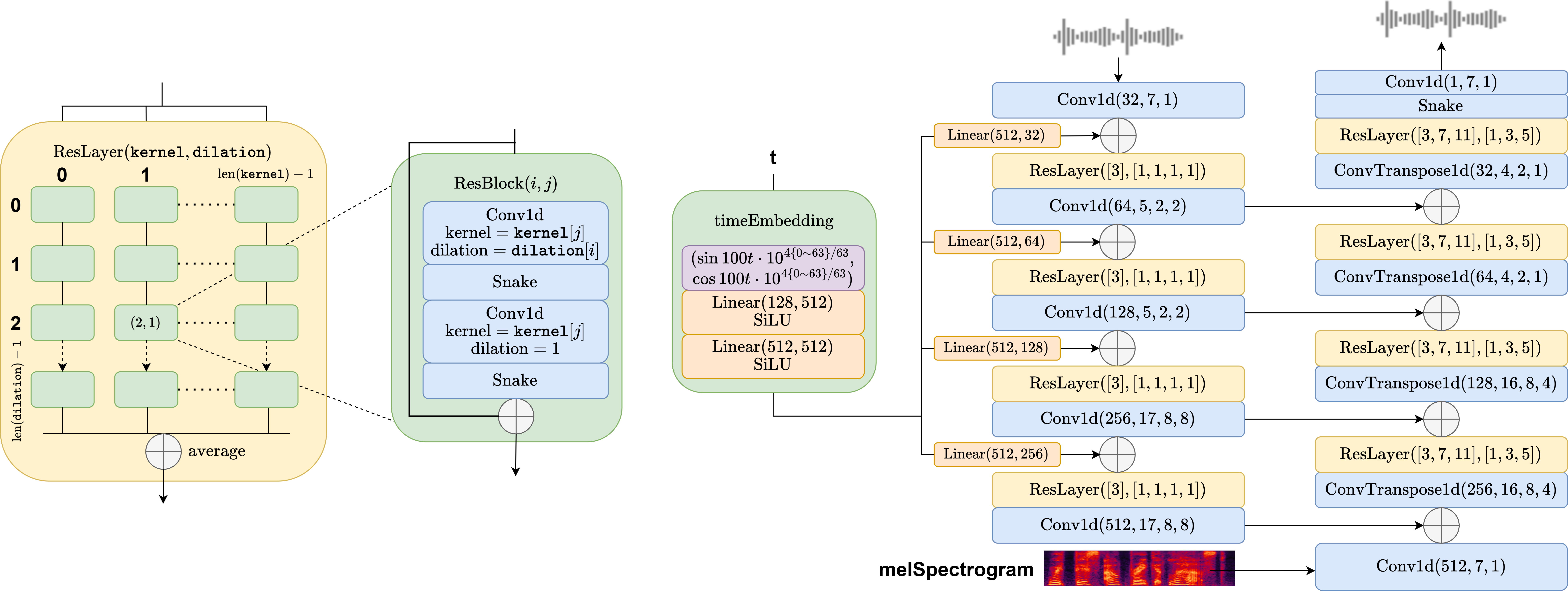
The total amount of parameters is 19.5M. The 128-dim time embedding is expanded to 512-dim after two linear-SiLU layers, and is then reshaped to the desired shape of each resolution. Conv1d and ConvTranspose1d are set with parameters (output channel, kernel width, dilation, padding). In ResBlock Conv1d takes same padding. Each ResLayer is defined with a kernel list and a dilation list, and their cross-product of define the shape of the ResBlock matrix and the convolutional layers of each ResBlock. On the left column are downsampling ResLayers, each containing a 4 x 1 ResBlock matrix, while on the right columns are upsampling ResLayers, each containing a 3 x 3 ResBlock matrix, following the structure from HifiGAN. In each ResBlock the number of channels is unchanged.
For detailed parameter settings please refer to WaveFM/src/params.py.
Audio Samples
All models were trained with 1M steps.
| Ground Truth |
WaveFM (6 steps) |
WaveFM (1 step) |
BigVGAN-base (1 step) |
PriorGrad (6 steps) |
DiffWave (6 steps) |
HifiGAN-V1 (1 step) |
FreGrad (6 steps) |
FastDiff (6 steps) |
| MUSDB18-HQ Mixture 1 | ||||||||
| MUSDB18-HQ Mixture 2 | ||||||||
| MUSDB18-HQ Mixture 3 | ||||||||
| MUSDB18-HQ Mixture 4 | ||||||||
| MUSDB18-HQ Mixture 5 | ||||||||
| MUSDB18-HQ Mixture 6 | ||||||||
| MUSDB18-HQ Bass 1 | ||||||||
| MUSDB18-HQ Drum 1 | ||||||||
| MUSDB18-HQ Vocal 1 | ||||||||
| MUSDB18-HQ Vocal 2 | ||||||||
| MUSDB18-HQ Vocal 3 | ||||||||
| MUSDB18-HQ Others 1 | ||||||||
| LibriTTS Test 1 | ||||||||
| LibriTTS Test 2 | ||||||||
| LibriTTS Test 3 | ||||||||
| LibriTTS Test 4 | ||||||||
| LibriTTS Test 5 | ||||||||
| LibriTTS Test 6 | ||||||||
| LibriTTS Test 7 | ||||||||
| LibriTTS Test 8 | ||||||||
| LibriTTS Test 9 | ||||||||
| LibriTTS Test 10 | ||||||||
| LibriTTS Test 11 | ||||||||
| LibriTTS Test 12 | ||||||||